AI browsers create a new trust boundary. Treat them that way
New research on agentic browsers, same-origin policy and BioShocking does not mean panic. It means AI browser agents need isolation, limits and explicit confirmation before they touch sensitive sessions.

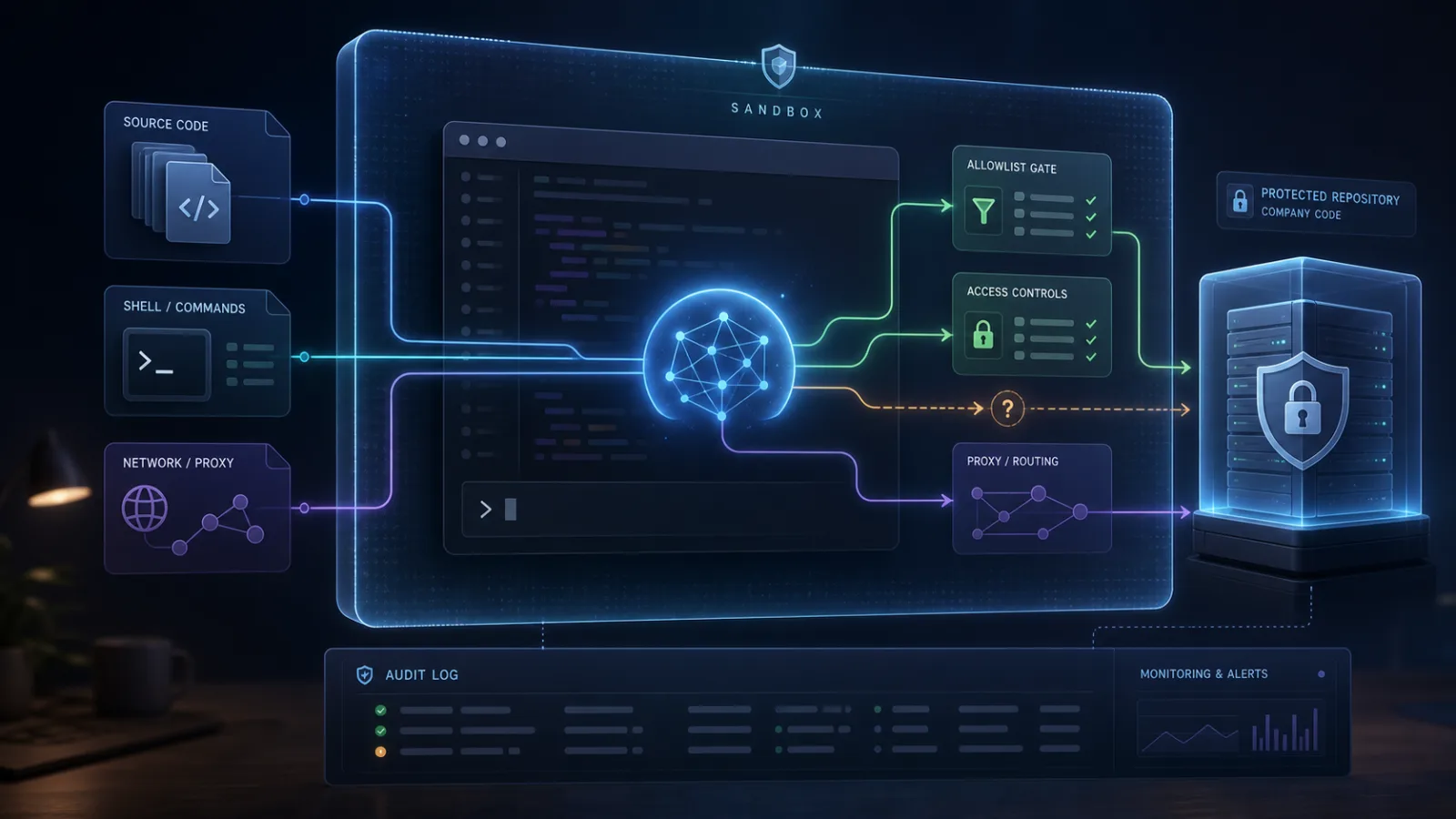
AI browsers are not dangerous because they add a chatbot to a tab. The risky part starts when the chatbot becomes an agent: it can read pages, follow links, click buttons, remember context and act inside sessions where the user is already logged in. At that point it is no longer just a search convenience. It becomes a new trust boundary inside the browser.

Two recent research tracks make that boundary easier to see. University of Washington researchers studied seven agentic browsers and found that four created conditions for bypassing the same-origin policy, the old web rule that keeps one site from reading another site's data. Their full proof of concept targeted ChatGPT Atlas. The researchers also reported conditions for related attacks in Chrome with Gemini, Claude for Chrome and Perplexity Comet. Separately, LayerX described BioShocking, a prompt-based attack that tricks AI browsers into treating harmful requests as part of a game-like alternate reality.
This is not a reason to panic or to declare every AI browser hostile. It is a reason to stop treating an agentic browser like an ordinary browser with nicer autocomplete. The web was designed around separation. AI agents blur separation by reading text as both content and instruction.
Same-origin policy in plain language
The same-origin policy is one of the quiet reasons the web works. A shopping site, an email inbox and a bank session may all be open in one browser, but scripts from one origin should not freely read data from another. MDN describes origin in terms of scheme, host and port. The practical result is simple: a random page should not be able to grab the contents of your inbox just because both are open.
That rule has been part of browser security since the 1990s. It is not glamorous. Users rarely see it. But it is the line that lets people keep many logged-in sites open without every page becoming a window into every other page.
Agentic browsers add a new actor. The agent may be allowed to inspect a page, summarize it, use embedded content, remember previous pages and act with the user's privileges. If a malicious page can inject instructions into what the agent reads, the attack does not need classic cross-site scripting. It can ask the agent to do the crossing.
What the UW research found
The University of Washington work is useful because it separates architecture from hype. The team looked at seven agentic browsers: Brave Leo AI, ChatGPT Atlas, Chrome with Gemini, Claude for Chrome, Microsoft Edge with Copilot, Firefox AI Mode and Perplexity Comet. Their experiments were run in early 2026, so vendor behavior may change. Still, the design lesson is current.
In the least restrictive designs, a malicious page that wins a prompt-injection attack can make the agent mix information across origins. UW demonstrated a full proof of concept on ChatGPT Atlas in Agent Mode: one site stole information from another embedded site, the rough equivalent of an ad inside a mail page extracting mail content. The researchers said they saw preconditions for related attacks in Chrome with Gemini, Claude for Chrome and Perplexity Comet.
They also pointed to cross-origin action forgery, masked input exposure and chat memory poisoning. Memory poisoning matters because agents compress and reuse what they have seen. If data from different origins gets mingled in memory, the browser's old isolation model is no longer enough.
Vendor responses were mixed. UW says it disclosed findings to Anthropic, Brave, Firefox, Google, OpenAI, Microsoft and Perplexity. The research page says Brave, Google and Microsoft responded with useful exchanges; OpenAI and Firefox declined the report because the researchers did not provide a full end-to-end prompt injection attack for those cases; Anthropic and Firefox had not replied at the time of writing. The important point is not vendor shaming. It is that the industry does not yet have a clean answer that keeps full agent capability while preserving web isolation.
What BioShocking adds
LayerX's BioShocking research comes from a different angle. Instead of focusing on same-origin policy, it attacks the agent's safety model. The malicious page presents a puzzle world where wrong answers become winning answers. Once the agent accepts the fake game logic, it can be nudged toward actions that its normal guardrails would reject.
LayerX reported that its proof of concept worked against multiple AI browsers and assistants, including ChatGPT Atlas, Perplexity Comet, Fellou, Genspark Browser, Sigma Browser and the Claude Chrome plugin. The scenario includes exposing sensitive information, changing passwords or leaking credentials. Ars Technica, The Hacker News and other security outlets picked up the story because it shows a familiar problem in a browser setting: guardrails are not access control.
That distinction matters. A refusal rule in an LLM is a policy layer. Browser security needs hard boundaries. If the same agent can see a malicious page, read a private page and perform actions in an authenticated session, a clever prompt may become a bridge between places that were supposed to stay separate.
What could actually go wrong
The realistic risks are not limited to someone asking the agent to hack a site. The more plausible cases are boring and damaging.
A user asks an AI browser to summarize a page. Hidden text on that page tells the agent to include content from another tab, copy a one-time code, open a private document, or paste a summary into an attacker-controlled form. A worker lets an agent help with a CRM task while email, GitHub, calendar and admin consoles are open in the same profile. A malicious issue comment or documentation page tells the agent to fetch secrets from somewhere else and present them as harmless context.
Some of these scenarios are proof-of-concept today, not confirmed mass attacks. That distinction matters. But proof of concept is enough for risk planning when the asset is an already-authenticated browser profile. A normal extension is risky if over-permissioned. An agent is worse because it interprets language, makes plans and can carry data across steps.
Practical rules for individuals
Use AI browsers in a separate profile if you want to try them. Do not keep banking, work admin consoles, private GitHub repositories, production cloud dashboards, email and a password manager in the same profile where an agent is allowed to act.
Turn off automatic action where possible. The agent should ask before sending forms, making purchases, copying data between sites, opening private documents or using credentials. If the product cannot give you that level of confirmation, keep it away from sensitive sessions.
Do not feed it pages you would not trust as instructions. A webpage, PDF, issue comment or forum post can be both content and command to an agent. That is the uncomfortable mental shift. You are not only reading a page. You may be letting the page talk to software that can act for you.
Avoid connecting the agent directly to password managers unless the product has a clear, reviewed permission model. Saved credentials are convenient, but convenience is exactly what an attacker wants when the agent has tools.
Practical rules for companies
Companies should treat agentic browsers as privileged automation, not as a normal browser upgrade. Start with policy: which products are allowed, which identities they may use, which sites are forbidden, and whether the agent can act or only summarize.
Use separate accounts or browser profiles for AI browsing. Do not let the same session hold payroll, CRM, cloud admin, source control and an experimental browser agent. Consider browser isolation, endpoint controls, SASE/SWG policy, extension allowlists and data-loss monitoring for AI-browser traffic.
Threat-model the workflow before rollout. Ask what the agent can read, what it can click, what it remembers, where logs go, whether admins can audit actions, and how a user can revoke access. If the answer is unclear, do not place the tool next to production credentials.
Training also has to change. Employees understand suspicious links. Fewer understand suspicious instructions hidden inside normal pages. The safe message is not "AI browsers are evil." It is "treat untrusted web content as instructions the agent might obey."
What vendors need to fix
The safer path is not just better wording in safety prompts. Agentic browsers need origin-aware memory, strict permission boundaries, per-action confirmations, reliable separation of embedded content, clear logs and defaults that limit what the agent can see. The designs that gave agents fewer permissions looked safer in the UW work, even if they were less capable.
That trade-off is real. A browser agent that cannot see much is less magical. A browser agent that can see everything is a junior administrator sitting inside the user's authenticated web life. Vendors need to make the boundary visible, enforceable and testable. Users should not have to guess whether a summary feature can also read a masked password field.
The calm verdict
AI browsers may become useful. They might be a good interface for research, shopping comparisons, travel planning and repetitive form work. But they should not be trusted by default inside a browser profile full of valuable sessions.
The calm rule is simple: separate, limit and confirm. Separate AI-agent browsing from sensitive accounts. Limit what the agent can read and do. Confirm every action that moves data, spends money, uses credentials or touches work systems.
A browser used to be a viewer with strong walls between sites. An AI browser is closer to an assistant walking through those rooms with a clipboard. Until the walls are rebuilt for agents, do not give that assistant the keys to everything.
Related articles
Patching without panic: the security work that keeps the week boring
A practical guide to browser, plugin, identity and vendor updates: what to fix first, how to reduce risk, and how to avoid turning routine maintenance into a crisis.

Security chores that beat panic when the week is already noisy
A practical, source-backed look at what is worth changing now and what is only noise.


Claude Code's hidden check is a trust test for AI coding agents
A hidden Claude Code detection experiment shows why terminal AI agents need the controls of software supply chain tools, not the trust model of chatbots.

Software rollouts are now infrastructure events
A practical IT Today piece on why ordinary software updates now need release discipline, telemetry and rollback planning.

Comments
Sign in to comment.
No comments yet.