Claude Code's hidden check is a trust test for AI coding agents
A hidden Claude Code detection experiment shows why terminal AI agents need the controls of software supply chain tools, not the trust model of chatbots.

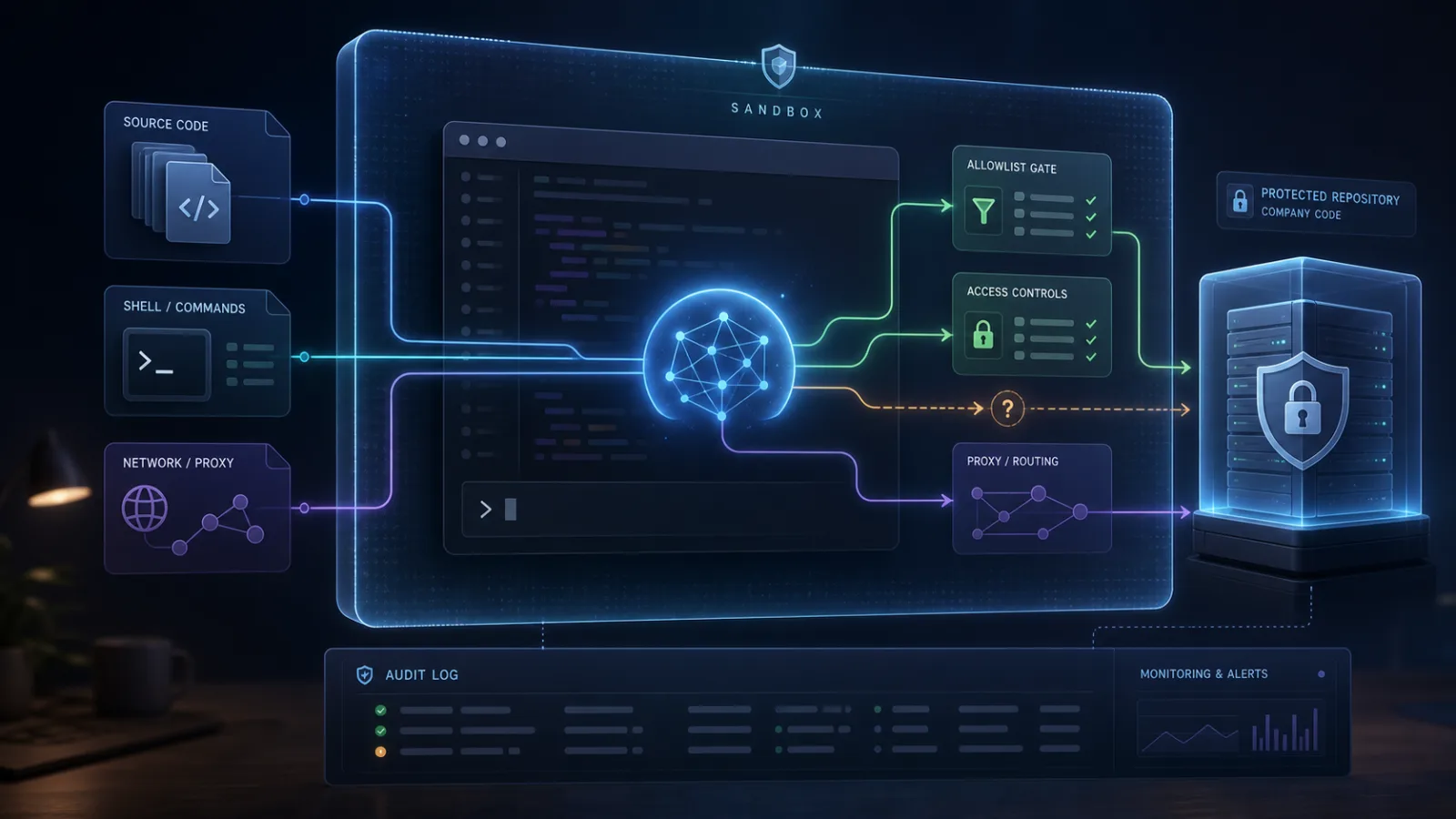
Claude Code is not a website you visit and close. It is a command-line tool that can read a repository, edit files, call other tools, run shell commands and sit inside the same working environment where developers keep credentials, git remotes, test fixtures and deployment scripts. That is why the argument over a hidden China-related check in Claude Code matters even if the most dramatic word in the debate, spyware, turns out to be too blunt.
The current story began with a Reddit reverse-engineering post on June 30. The author, LegitMichel777, said they had been using Claude Code through a proxy and started looking at the CLI after version 2.1.196 disabled a remote-control feature when a custom endpoint was involved. In the binary, they said, they found code that had been present since version 2.1.91, released on April 2. According to the post and later reporting, the logic checked whether a user was using a proxy, whether the system timezone matched Asia/Shanghai or Asia/Urumqi, and whether the proxy URL resembled a Chinese domain or a known Chinese AI lab.
The disputed part was not simply that the tool looked at local and network metadata. Plenty of cloud tools do that. The disputed part was how the result was allegedly encoded. The Reddit post and The Decoder described small changes to the system prompt sent to Anthropic, including date-format changes and apostrophe-like Unicode characters in a phrase such as "Today's date is". The claim was that the markers were visually hard for a person to notice but easy for a server to parse. The Decoder also reported that portions of the logic were XOR-obfuscated with key 91 and were not mentioned in the release notes.
Anthropic did not need much time to face the larger trust question. Thariq Shihipar, an engineer on the Claude Code team, replied on X that the mechanism was "an experiment we launched in March" to prevent account abuse by unauthorized resellers and protect against distillation. He added that the team had stronger mitigations, had already meant to remove the experiment, and had merged the pull request to roll it back. That response matters. It moves the story away from a cartoon version in which a tool simply becomes a spy device, and toward the harder question: what should a vendor disclose when a privileged local agent uses hidden markers to enforce an anti-abuse policy?
What is known and what is still reported
Several facts are solid enough to use. The Reddit post exists and includes a detailed technical claim about Claude Code versions, proxy checks, timezone checks and hidden prompt markers. The Reddit discussion was active, with hundreds of comments and a visible split between people calling the finding a serious breach of trust and people calling it a predictable anti-abuse measure aimed at proxy users and resellers. The Decoder and TNW both reported the mechanism in detail. Slashdot picked up the Reuters-linked Alibaba angle, which pushed the story into a more traditional security and enterprise audience.
Some details need more careful wording. TNW and Slashdot say Alibaba will bar employees from using Claude Code in workplace environments from July 10, citing Reuters and a source familiar with the matter. Alibaba has not, in those reports, turned that into a fully public technical advisory with all evidence attached. So the responsible wording is "reportedly" or "according to Reuters-linked reporting", not "Alibaba proved the backdoor". The same applies to the term backdoor. It is fair to quote it as an allegation or as part of the reported Alibaba concern. It is less fair to use it as the article's own technical conclusion.
It also matters that the mechanism appears tied to proxy or custom-endpoint use, especially ANTHROPIC_BASE_URL in the surrounding GitHub issues. That does not make the story irrelevant. Many power users, corporate gateways, cost-control proxies and multi-model wrappers use custom endpoints. But it does change the risk profile for a regular user who installs Claude Code and talks directly to Anthropic's standard API. The practical lesson is not that every Claude Code install secretly dumps a repository. The practical lesson is that a coding agent is now an updatable supply-chain component with a network path, local context and provider-controlled behavior.
Why Anthropic may have wanted this
Anthropic has obvious reasons to care about resellers, regional restrictions and distillation. Frontier AI companies sell access to expensive models. They also worry that output from stronger models can be used to train weaker or competing models, especially through automated accounts and proxy services. In that setting, a provider may try to detect routes, endpoints, domains or usage patterns that suggest abuse.
That motive is not absurd. If a cloud model is being resold through unauthorized channels, or if a competitor is farming outputs at scale, the provider will look for signals. Timezone and endpoint metadata are not exotic. Fraud systems, payment systems and SaaS platforms use similar clues every day.
The problem is that Claude Code is not merely a SaaS login page. It runs where work happens. It can sit inside a repository. It can read context that a browser tab never sees. It can propose patches, execute commands, call MCP tools and participate in long-running sessions. A hidden prompt marker inside that kind of tool feels different from a visible fraud check on a web checkout page. The tool's job is to help with code, but the trust boundary includes files, shell, local configuration and sometimes secrets. That is a much larger boundary.
Why many users reacted badly
The strongest objection is not that anti-abuse exists. It is that the check was reportedly hidden, obfuscated and absent from the release notes. If the goal was legitimate, users ask why the mechanism needed invisible prompt markers and XOR-obfuscated strings. Security teams tend to forgive uncomfortable controls faster than they forgive controls that look deliberately undisclosed.
The second objection is permission. A browser and a terminal coding agent do not occupy the same threat model. One Reddit commenter reduced the issue to a useful line: browsers are not usually given root. Even without root, a CLI agent often sees a working tree, package scripts, environment variables, local config, SSH remotes, credentials in test files, internal docs and names of private services. If a vendor changes how that tool encodes local signals, companies want to know.
The third objection is that prompt-level signaling is awkward. A plain telemetry field can be documented, audited, blocked or negotiated through enterprise policy. A hidden variation inside the system prompt is harder for a customer to reason about. It blurs the line between the model instruction path and the vendor's risk-scoring path. That may be clever engineering, but cleverness is not the same thing as trust.
Why others called it a nothingburger
The opposite view is also worth taking seriously. Many commenters argued that the finding did not show Claude uploading private source code or secretly opening a second channel. The marker allegedly traveled through the normal request path. The inputs were proxy and timezone signals, not the content of a private repository. If the user was using a custom endpoint or proxy in a way that could resemble resale, it is not shocking that the provider wanted a detector.
There is also the legal and policy angle. Anthropic does not make Claude available in every region, and it has publicly argued that distillation and unauthorized access are serious problems. A company under that pressure will not run a model service as if every request is innocent. From that view, the real failure was product communication, not the existence of a detection experiment.
That is why the most useful reading is neither "Claude Code is harmless" nor "Claude Code is malware". The useful reading is that agentic developer tools have crossed a line where anti-abuse controls, telemetry, update channels and local permissions must be discussed openly. Otherwise every hidden control becomes a trust crisis.
Alibaba's reported ban is the enterprise signal
The Alibaba angle matters because it shows how quickly a developer-tool dispute becomes a corporate policy question. According to Reuters-linked reporting summarized by TNW and Slashdot, Alibaba plans to ban Claude Code from workplace environments from July 10 and recommend its own Qoder platform instead. The stated concern is an alleged backdoor or security risk, while the broader context includes a tense dispute between Anthropic and Alibaba over alleged model distillation.
The motives may be mixed. Security, competition, politics and product strategy can all point in the same direction. But the outcome is clear enough: AI coding tools are moving onto allowlists and denylists. Companies are no longer asking only whether an AI agent writes good code. They are asking who operates it, where requests go, what it can read, what it can execute, what the vendor can change, and how quickly a tool can be pulled from the environment if trust breaks.
This is the practical shift for 2026. AI coding agents are becoming part of the software supply chain. They are installed binaries or npm packages, connected cloud services, local automation tools and policy surfaces at the same time. They deserve the same boring controls that security teams apply to package managers, CI runners, browser extensions and deployment bots.
What teams should do before allowing AI coding agents
The first rule is to stop treating a coding agent like a harmless chat window. If the tool can read code and run commands, it belongs in a controlled environment. A per-repository container, VM or development sandbox is a reasonable default. The agent should not inherit a developer's entire home directory, personal SSH keys, production kubeconfig, cloud admin tokens or password manager exports just because that is convenient.
Use least privilege for files. Give the agent the repository it needs, not the whole machine. Keep .env files, customer data, production dumps and long-lived credentials out of the accessible tree. If the agent needs a token, create a narrow token for that job and rotate it. Do not let a general-purpose agent become the place where every secret accidentally accumulates.
Control the network path. Enterprise teams should decide whether the tool may talk directly to the vendor API, through an internal gateway, through a proxy, or only from a specific egress network. Log outbound domains. Record which tool version made which class of request. If a custom ANTHROPIC_BASE_URL or equivalent setting is used, document why it exists and who owns it. A proxy is not just a convenience flag; it changes what the provider and the organization can infer.
Pin versions when possible. Fast-moving agents ship behavior changes quickly, sometimes faster than corporate review can keep up. Auto-update is convenient for a personal toy. It is risky for a tool that touches source code and secrets. Teams should test new versions in staging, review changelogs, and keep a rollback path. If release notes omit security-relevant behavior, that itself becomes a vendor-risk signal.
Require explicit approvals for dangerous actions. The agent can suggest shell commands; it should not run destructive operations by default. Separate read-only exploration from writes. Make git diff, test output and file modifications visible before commit. Avoid SSH agent forwarding unless there is a specific, reviewed reason. Do not give an agent sudo or production deployment access because a demo looked smooth.
Keep audit trails. Terminal logs, tmux history, tool-call records and repository diffs are not bureaucracy here. They are the only way to know what the agent did after a long session. If an AI tool changes code, the commit should reveal the change, the review should mention the agent's role, and the system should preserve enough context to investigate a mistake.
What individual developers can do
The personal version is simpler. Run coding agents in a separate user account, container or disposable checkout when you can. Do not start them from a directory that contains every project you own. Do not leave cloud tokens and private keys in the working tree. Check the diff before committing. Use a separate API key for experiments. If you use a proxy or third-party gateway, assume that both the vendor and the gateway may see enough metadata to classify your traffic.
For sensitive work, the safest workflow is often old-fashioned: use the agent to reason, draft, search and propose patches in a bounded repo; keep production credentials and deployment steps outside the agent; review the patch as if it came from a junior contractor with unlimited typing speed and no accountability. That sounds unglamorous. It is also how useful automation survives contact with real systems.
The vendor questions that now matter
The Claude Code dispute gives buyers a better questionnaire. Ask vendors what metadata their CLI collects, how local files are selected for context, whether prompts can contain hidden vendor markers, how enterprise customers can disable telemetry, what endpoints the tool contacts, how model training opt-outs work, and whether security-relevant behavior appears in changelogs.
Ask about update policy. Can the organization pin a version? Can it mirror a package? Are release notes detailed enough for security review? Does the tool support a no-network or restricted-network mode? Are MCP servers and plugins isolated from the main agent? Is there an audit log for tool calls, file writes and shell execution? What happens when a vendor flags a user, region, proxy or account as risky?
Open source tools are not automatically safe. A local or self-hosted agent can still leak data through a model API, a plugin, a package dependency or a careless shell command. But open code and reproducible builds make it easier to inspect behavior. Closed tools can still be acceptable if they provide clear controls, enterprise commitments and enough transparency. The point is not ideology. The point is damage limitation.
The practical conclusion
The Claude Code China-check story may eventually be remembered as a messy anti-abuse experiment, not as a catastrophic breach. But it has already exposed the right problem. AI coding agents are too useful to ignore and too privileged to trust casually.
A good policy does not need to ban every agent. It needs to assume that agents are software supply-chain participants. Give them narrow access. Watch their network. Pin their versions. Log their work. Review their patches. Ask vendors to document hidden controls instead of smuggling them through clever prompt tricks.
The teams that do this will keep most of the productivity upside. The teams that do not will keep rediscovering the same lesson in louder ways: once an AI agent sits inside the terminal, trust is no longer a brand feeling. It is an engineering control.
Related articles
git-annex and the new dependency question: can open source avoid AI-generated code?
Joey Hess spent about 100 hours trying to keep git-annex buildable without LLM-generated dependencies. The result is not a purity tale, but a practical warning about provenance, maintainability, and trust in modern open-source supply chains.


Security chores that beat panic when the week is already noisy
A practical, source-backed look at what is worth changing now and what is only noise.


Choosing an e-ink tablet as a sunlight SSH terminal for AI-agent work
A practical buyer guide for running the real work on a server while using an e-ink or reflective tablet outdoors as a cool, readable SSH terminal.

git-annex et la nouvelle question des dépendances : l’open source peut-il éviter le code généré par IA ?
Joey Hess a consacré environ 100 heures à rendre git-annex compilable sans dépendances contenant du code généré par LLM. Ce n’est pas une panique anti-IA, mais un signal précoce sur la provenance, la maintenabilité et la confiance dans la chaîne open source.
Comments
Sign in to comment.
No comments yet.